Daniel Pocock: Calendar and Contact data with free software in the Smartphone era

Since the rise of smartphones, first Blackberry, then iPhone and now Android, the world at large has had a convenient option to fall back on for management of contact and calendar data.
The data itself seems somewhat trivial: many of us software developers have worked with a plethora of obscenely more obscure schemas. It is unlikely that most people would ever have to perform an operation on their address book that requires a statistical toolkit like the R project or any of the other advanced tools we now have for data processing. In terms of data, addresses and phone numbers can appear quite boring. So why hasn't the free software community mastered it and cloud providers are currently running rampant hoovering up the data of billions of users?
Ruling out LDAP
One problem that people have faced is the existence of different standards. LDAP has quite a high profile and appears to be supported by default in many desktop applications. For this reason, it tends to grab people's attention but after a close look, many people find it is not the right solution.
LDAP tends to work well for organisations where the data is centrally managed and in situations where fine-grained access control is not required. LDAP servers often need a capable UNIX administer to manage effectively. To top it off, LDAP itself does not provide an effective solution for two-way synchronization of data with remote and mobile users.
The emergence of SyncML, CalDAV, GroupDAV and CardDAV
Addressing this final problem (two-way mobile/portable device sync) has brought on the development of further standards.
Initially, SyncML (now known as Open Mobile Alliance Data Synchronization and Device Management) grabbed significant attention, partly because it had been included in some of the first generation of smartphones from once-prominent vendors like Nokia.
Open source server solutions for SyncML did not gain traction though. The most prominent is Funambol, however, it is not packaged in any major Linux distribution and it requires some basic Java knowledge to maintain it effectively. Like LDAP it appears to be most comfortable in enterprise use cases and doesn't appeal to the people who run a private mail and web server. SyncML has further suffered with the lack of support in more recent generations of smartphones.
WebDAV was formalised in 1999 and there are now various derivative standards such as CalDAV and CardDAV which use WebDAV as a foundation. However, standards didn't arrive at this place directly: CalDAV only appeared as RFC 4791 in 2007 and CardDAV as RFC 6352 in 2011. In the meantime, some vendors experiemented with an alternative called GroupDAV. GroupDAV is largely obsolete now and GroupDAV v2 is a subset of CalDAV and CardDAV.
Finally gaining traction
The good news is, CardDAV and CalDAV are gaining traction, in no small part due to support from Apple and the highly proprietary iPhone. Some free software enthusiasts may find that surprising. It appears to be a strategic move from Apple, using open standards to compete with the dominance of Microsoft Exchange in large corporate networks.
Both protocols are supported natively in iPhones and Mac OS X. More exciting, Apple releases their Contacts Server and Calendar Server as open source software, making it easier to look under the hood and observe any deviations from the standards.
Apple's adoption of CardDAV and CalDAV has been accompanied by a similar effort in free software, however, support is more patchy. The Mozilla Lightning calendar plug-in for Thunderbird (known as the iceowl-extension plugin for icedove on Debian) has supported CalDAV for some time. In contrast, Thunderbird's address book lacks native support for CardDAV and has other limitations (discussed in detail below). Limited CardDAV support in Thunderbird can be achieved using the third-party SOGo Connector, which is not just for ScalableOGo server. The Evolution PIM appears to support both CardDAV and CalDAV relatively smoothly and appears to be more functional and easier to get started with.
Free software servers are also emerging. DAViCal, despite the name, supports both CardDAV and CalDAV. It is a good solution for people who have an existing mail server and don't want to transition to an all-in-one groupware suite. Packages available in Debian make it easy to deploy and get started. It is a PHP solution, using a PostgreSQL database underneath. For people who do want a groupware suite, CardDAV and CalDAV are supported in products like ScalableOGo and Zimbra. For people who don't want a server at all and just want to sync between a desktop and a mobile device, there are options like Calypso.
Mobile support: the missing link
A number of people have blogged about using the Android apps CardDAV-Sync and CalDAV-Sync to complete the picture.
I've tested these myself and verified that they work. However, there is one vital thing missing: the source code. Nobody knows what is inside these apps except the developer. That makes it impossible for other developers to troubleshoot them and improve them and it also makes it impossible to be certain that they do not leak information.
An alternative is the aCal app for Android. Despite the name, aCal can synchronize the address book as well as the calendar. However, in my tests against DAViCal, I found that the addressbook can only be synced once and that on subsequent syncs, it fails to discover any new server-side contacts. aCal source code is available on gitorious.
aCal appears to be a compelling solution for Android users, hopefully the contact sync will be fixed soon. It only syncs once after installation and then fails to detect any new contacts. Thunderbird's limitations It has already been mentioned that the Thunderbird address book can be synchronized to a CardDAV server by adding the SOGo Connector plugin. However, this is not a perfect solution. The plugin itself is fine: the SOGo web site describes the connector (as opposed to the SOGo Integrator plugin) as a portable solution: in other words, it is vendor neutral, compatible with any standards-compliant server. The first limitation is that it is necessary to duplicate the setup process for both the calendar sync and the address book sync. This is just a question of convenience.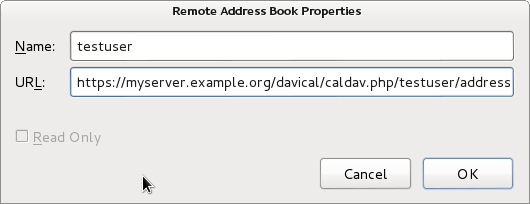
The SOGo Connector plugin configuration window is very trivial. I recommend using read-only mode to avoid the problems with multiple email addresses or telephone numbers. More serious limitations exist in the address book itself: if the CardDAV server has more than 2 email addresses, they will not appear in the Thunderbird address book. Changing an email address on the client side will result in loss of those additional email addresses on the server-side. The Mozilla team initially committed to rewrite the address book from the ground up but it is not clear whether that work is still in progress. DAViCal confusion I had been using DAViCal for quite some time as a CalDAV server before I recently decided to try and use it for CardDAV as well. As a calendar server, it had been working fine. I have a small number of users with some private calendars and also some shared calendars. When I installed the SOGo Connector plugin and went to setup the client-side configuration, it asked me for the server URL. Having used CalDAV already, I simply tried copying the existing CalDAV URL, which is of the form https://myserver.example.org/davical/caldav.php/daniel/home The URL was accepted and I could create address book entries on the client side. No errors appeared. I then tried setting up the same URL as an address book in Evolution. This time, I found I was able to create contacts and sync them to the server and access them from another copy of Evolution. It appeared DAViCal was working fine and I felt that Thunderbird or the SOGo Connector was somehow broken, because the Evolution clients were syncing but Thunderbird was not. The lack of any errors from the Thunderbird GUI further undermined my confidence in the SOGo Connector. Nonetheless, I decided to dig a little deeper, looking through the DAViCal source code. This brought me to the realisation that each URL could be flagged as either a calendar resource or an address book resource. This had not been obvious to me before. Evolution had effectively been storing the contact entries into a calendar URL and DAViCal had been happily accepting them. SOGo Connector, querying the URL, appears to have received both calendar and contact records from DAViCal and given up.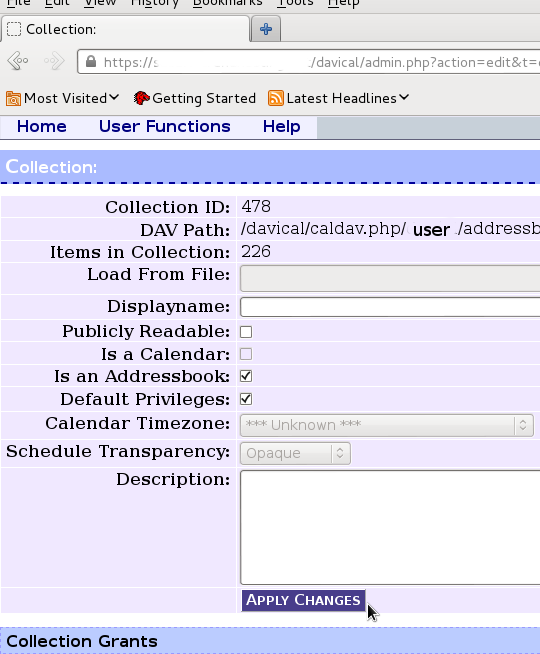
Here is where I configured the extra resource for an address book store under my user account in DAViCal In the DAViCal web management console, I created an extra resource for my user ID and set the appropriate checkbox to mark the resource as an address book. Then I put this resource URL into all the clients and found that they were all able to sync with each other. DAViCal's maintainer has explained that this is a limitation in the CardDAV/CalDAV protocols: technically, it is valid for the client to store the wrong type of objects in each URL. Clients need to be more resilient when they stumble across objects they don't expect in a particular resource. Conclusion A complete free software based contact-management solution can be easily deployed using any of the servers mentioned above, particularly if Evolution is the preferred client software. Using Thunderbird as a client, it can also work, but attention is needed to avoid data loss on sync. Thunderbird could also be used in a read-only mode to access address books maintained with Evolution. Mobile support is still patchy on Android. The closed source solution (CardDAV-Sync and CalDAV-Sync) appears to work and a promising open source close, aCal, appears to be "nearly there". Some people would obviously prefer to use a standalone contact/calendar server, while others may prefer an all-in-one groupware suite. Both approaches appear to be feasible, but the standalone contact/calendar server appears to offer a more compelling way to start quickly and have minimal administrative overhead, particularly due to the fact that DAViCal is available in a supported package.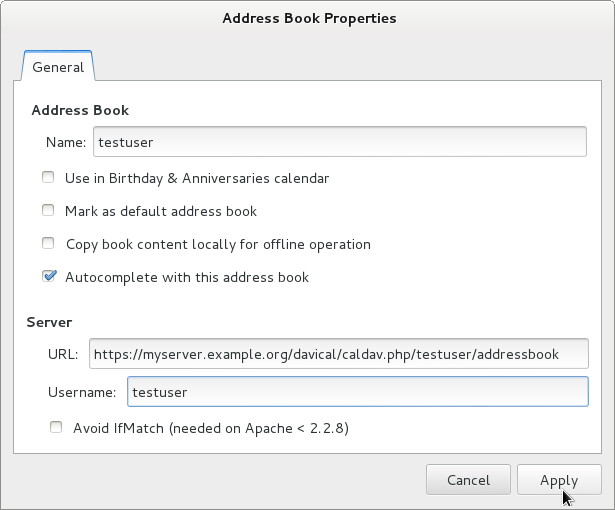
This is the contact server configuration window in Evolution. It offers slightly more options than SOGo Connector in Thunderbird and appears to be a more finished solution overall.
aCal appears to be a compelling solution for Android users, hopefully the contact sync will be fixed soon. It only syncs once after installation and then fails to detect any new contacts. Thunderbird's limitations It has already been mentioned that the Thunderbird address book can be synchronized to a CardDAV server by adding the SOGo Connector plugin. However, this is not a perfect solution. The plugin itself is fine: the SOGo web site describes the connector (as opposed to the SOGo Integrator plugin) as a portable solution: in other words, it is vendor neutral, compatible with any standards-compliant server. The first limitation is that it is necessary to duplicate the setup process for both the calendar sync and the address book sync. This is just a question of convenience.
The SOGo Connector plugin configuration window is very trivial. I recommend using read-only mode to avoid the problems with multiple email addresses or telephone numbers. More serious limitations exist in the address book itself: if the CardDAV server has more than 2 email addresses, they will not appear in the Thunderbird address book. Changing an email address on the client side will result in loss of those additional email addresses on the server-side. The Mozilla team initially committed to rewrite the address book from the ground up but it is not clear whether that work is still in progress. DAViCal confusion I had been using DAViCal for quite some time as a CalDAV server before I recently decided to try and use it for CardDAV as well. As a calendar server, it had been working fine. I have a small number of users with some private calendars and also some shared calendars. When I installed the SOGo Connector plugin and went to setup the client-side configuration, it asked me for the server URL. Having used CalDAV already, I simply tried copying the existing CalDAV URL, which is of the form https://myserver.example.org/davical/caldav.php/daniel/home The URL was accepted and I could create address book entries on the client side. No errors appeared. I then tried setting up the same URL as an address book in Evolution. This time, I found I was able to create contacts and sync them to the server and access them from another copy of Evolution. It appeared DAViCal was working fine and I felt that Thunderbird or the SOGo Connector was somehow broken, because the Evolution clients were syncing but Thunderbird was not. The lack of any errors from the Thunderbird GUI further undermined my confidence in the SOGo Connector. Nonetheless, I decided to dig a little deeper, looking through the DAViCal source code. This brought me to the realisation that each URL could be flagged as either a calendar resource or an address book resource. This had not been obvious to me before. Evolution had effectively been storing the contact entries into a calendar URL and DAViCal had been happily accepting them. SOGo Connector, querying the URL, appears to have received both calendar and contact records from DAViCal and given up.
Here is where I configured the extra resource for an address book store under my user account in DAViCal In the DAViCal web management console, I created an extra resource for my user ID and set the appropriate checkbox to mark the resource as an address book. Then I put this resource URL into all the clients and found that they were all able to sync with each other. DAViCal's maintainer has explained that this is a limitation in the CardDAV/CalDAV protocols: technically, it is valid for the client to store the wrong type of objects in each URL. Clients need to be more resilient when they stumble across objects they don't expect in a particular resource. Conclusion A complete free software based contact-management solution can be easily deployed using any of the servers mentioned above, particularly if Evolution is the preferred client software. Using Thunderbird as a client, it can also work, but attention is needed to avoid data loss on sync. Thunderbird could also be used in a read-only mode to access address books maintained with Evolution. Mobile support is still patchy on Android. The closed source solution (CardDAV-Sync and CalDAV-Sync) appears to work and a promising open source close, aCal, appears to be "nearly there". Some people would obviously prefer to use a standalone contact/calendar server, while others may prefer an all-in-one groupware suite. Both approaches appear to be feasible, but the standalone contact/calendar server appears to offer a more compelling way to start quickly and have minimal administrative overhead, particularly due to the fact that DAViCal is available in a supported package.
This is the contact server configuration window in Evolution. It offers slightly more options than SOGo Connector in Thunderbird and appears to be a more finished solution overall.
 Altimeter Testing at Airfest
Bdale and I, along with AJ Towns and Mike Beattie, spent last weekend
in Argonia, Kansas, flying rockets with our Kloudbusters friends at
Altimeter Testing at Airfest
Bdale and I, along with AJ Towns and Mike Beattie, spent last weekend
in Argonia, Kansas, flying rockets with our Kloudbusters friends at




 XInput2 has the ability to deliver raw device events right to
applications, bypassing the whole event selection mechanism within the
X server. This was designed to let games and other applications see
relative mouse motion events and drawing applications see the whole
tablet surface.
These raw events are really raw though; they do not include the
cursor position, and so cannot be directly used for tracking.
However, we do know that the cursor only moves in response to input
device events, so we can easily use the arrival of a raw event to
trigger a query for the mouse position.
A better plan?
Perhaps what we should do is to actually create a new event type to
report the cursor position and the containing window so that
applications can simply track that. Yeah, it s a bit of a special
case, but it s a common requirement for accessibility tools.
XInput2 has the ability to deliver raw device events right to
applications, bypassing the whole event selection mechanism within the
X server. This was designed to let games and other applications see
relative mouse motion events and drawing applications see the whole
tablet surface.
These raw events are really raw though; they do not include the
cursor position, and so cannot be directly used for tracking.
However, we do know that the cursor only moves in response to input
device events, so we can easily use the arrival of a raw event to
trigger a query for the mouse position.
A better plan?
Perhaps what we should do is to actually create a new event type to
report the cursor position and the containing window so that
applications can simply track that. Yeah, it s a bit of a special
case, but it s a common requirement for accessibility tools.
 One of the replies to the post about
One of the replies to the post about 



 Floating and tiling window managers
In the X Window System, the window manager is that piece of software that places
your windows and allows you to move them, resize them, hide them, etc. If your windows
have titles on top of them, with buttons to close them or reduce them, it is thanks to
the window manager. There are two major types of window managers:
Floating and tiling window managers
In the X Window System, the window manager is that piece of software that places
your windows and allows you to move them, resize them, hide them, etc. If your windows
have titles on top of them, with buttons to close them or reduce them, it is thanks to
the window manager. There are two major types of window managers: